Latar Belakang
Kanker payudara merupakan penyakit yang sangat berbahaya bagi tubuh kita. Pada tahun 2012 menurut International agency for research of cacer (IARC) sebanyak 19,2 % dari penderita kanker, merupakan penderita kanker payudara. Bisa dihitung sebanyak 2.701.036 jiwa telah mengidap penyakit ini.pencatatan ini dilakukan untuk mengatisipasi pasien sejak dini agar tidak terjangkit penyakit kanker payudara.
Data mining merupakan kegiatan yang meliputi pengumpulan dan pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data. Output dari data mining dapat dipakai untuk memperbaiki pengambilan sebuah keputusan di masa depan. Data ming memiliki kaitan dengan berbagai bidang ilmu yang lain seperti Machine Learning, Statistik, Visualisasi serta database
Dengan data tersebut, bisa ditemukan sebuah cara antisipasi secara dini dengan menggunakan data mining. Data mining dapat menjadikan data yang sebelumnya tidak berarti menjadi sebuah informasi atau pola dengan proses tertentu. Data mining juga memungkinkan terbentuknya sebuah model ataupun aturan dalam data yang sebelumnya tidak berharga. Oleh karena itu data yang ditemukan bisa diolah dengan menggunakan metode metode didalam data mining untuk menjadikan data tersebut sebagai antisipasi dari penyakit kanker payudara.
Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah sebagai implementasi Data Mining pada data statistik breast cancer di negara Yugoslavia pada tahun 1998 untuk menentukan ciri–ciri kekambuhan penyakit kanker payudara.
Perumusan Masalah
Penelitian yang telah dilakukan memiliki batasan masalah sebagai berikut:
1. Data yang digunakan untuk penelitian berasal dari UCI 2. Tools yang digunakan menggunakan bahasa java dan memanfaatkan library dari weka.jar
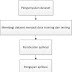
Metodologi Penelitian
 |
| Flowchart Metodologi Penelitian. |
Menurut alur pengerjaan diatas maka berikut ini adalah metodologi yang akan diterapkan terhadap data yaitu :
1. Pre-processing: tahap pre-processing ini adalah tahap pencarian data dan pemilihan teknik data mining beserta metode yang akan digunakan. Data yang sudah didapat kemudian dibagi menjadi 2 untuk data training dan data uji
2. Main process: pada tahap proses utama ini adalah proses pembuatan program yang sesuai dengan metode yang dipilih kemudian mengimplementasikan dataset tersebut kedalam aplikasi. Proses utama dari program yaitu mengambil dataset, mengambil data training, lalu generate data.
3. Post-processing: tahap post-processing adalah tahap mengetahui apakah hasil dari implementasi tersebut telah sesuai atau tidak. Jika tidak, maka akan dilakukan perbaikan terhadap program yang telah dibuat. Jika sesuai maka dapat diambil kesimpulan hasil perhitungan dari proses utama tersebut.
Hasil dan Pembahasan
Dataset ini berjudul Data kanker payudara. Dataset ini diperoleh dari https://archive.ics.uci.edu/ml/datasets.html. Dataset ini ditulis oleh Matjaz Zwitter & Milan Soklic (dokter) Institut Oncology University Medical Center Ljubljana, Yugoslavia dan merupakan donors dari Ming Tan and Jeff Schlimmer (Jeffrey.Schlimmer@a.gp.cs.cmu.edu) pada tanggal 11 july 1988. Kumpulan data ini mencakup 201 instance dari satu kelas dan 85 instance dari kelas lain dengan total data 286. Instance dijelaskan oleh 9 atribut, beberapa di antaranya adalah linear dan beberapa lainnya adalah nominal. Berikut atribut yang terdapat pada dataset:
1. Class: no-recurrence-events, recurrence-events2. age: 10-19, 20-29, 30-39, 40-49, 50-59, 60-69, 70-79, 80-89, 90-99.
3. menopause: lt40, ge40, premeno.
4. tumor-size: 0-4, 5-9, 10-14, 15-19, 20-24, 25-29, 30-34, 35-39, 40-44, 45-49, 50-54, 55-59.
5. inv-nodes: 0-2, 3-5, 6-8, 9-11, 12-14, 15-17, 18-20, 21-23, 24-26, 27-29, 30-32, 33-35, 36-39.
6. node-caps: yes, no.
7. deg-malig: 1, 2, 3.
8. breast: left, right.
9. breast-quad: left-up, left-low, right-up, right-low, central.
10. irradiat: yes, no.
Berikut ini adalah hasil dari pengujian:
 |
| Tampilan Hasil Pengujian Pada Aplikasi. |
Pada kolom kiri atas berisi data set yang digunakan. Pada kolom kanan atas merupakan data yang akan di training. Kolom kanan bawah merupakan hasil prediksi data dari dataset yang sudah di tes sesuai dengan data training. Kolom kiri bawah berisi hasil dari perhitungan Naïve Bayes dari hasil prediksi data.
Hasil dari perhitungan dataset dengan metode Naïve Bayes yaitu 73.1 % data terklasifikasi benar dan 26.9 % data terklasifikasi salah dari total 286 data. Hasil klasifikasinya yaitu sebagi berikut:
 |
| Tabel Hasil Pengujian. |
Data no-recurrence-events terdeteksi sebagai no-recurrence-events ada 172 data, data no-recurrence-events terdeteksi sebagai recurrence-events terdapat 29 data. Data recurrence-events yang terdeteksi sebagai no-recurrence-events terdapat 48 data. Dan data recurrence-events yang terdeteksi sebagai recurrence-events ada 37 data. Dengan hasil diatas, maka metode cocok untuk digunakan.
Kesimpulan
Data yang kami gunakan adalah data tentang kanker payudara yang berisi 286 data. Data tersebut kami hitung dengan Teknik klasifikasi data mining dengan metode Naïve Bayes. Dari hasil program kami yaitu ada 73.1 209% data terklasifikasi benar dan 26.9 % data terklasifikasi salah dari total 286 data. Maka metode Naïve Bayes ini cocok untuk menghitung dataset kanker payudara.
Daftar Pustaka
1. http://gsbipb.com/?p=821.2. Kurniawan, M Faizal dan Ivandari. 2017. Komparasi Algoritma Data Mining Untuk Klasifikasi Penyakit Kanker Payudara. Pekalongan. IC-Tech.
3. Wulan, Rayung. Lestari, Mei. Septiani, Ni Wiyan Parwati. 2017. Komparasi Algoritma Naïve Bayes Dan Knearest Neighbor Untuk Deteksi Kanker Payudara. Jakarta Selatan. Semantikom.
4. https://informatikalogi.com/algoritma-naive-bayes.
Klasifikasi Breast Cancer Menggunakan Metode Naïve Bayes
 Reviewed by Syafriansyah Muhammad
on
3/29/2019
Rating:
Reviewed by Syafriansyah Muhammad
on
3/29/2019
Rating:
Reviewed by Syafriansyah Muhammad
on
3/29/2019
Rating:






Tidak ada komentar: